Through digg, I found this amusing site... You complete a shorty survey and it indicates how many five year olds you could take in a fight.
I'm proud to say that I could take 32 of the little jerks in a fight.
32
Check out your score over at their website. (Oh, but make sure you edit the HTML they give you before you post it somewhere, they include a link to a payday advance website. boo).
Saturday, December 15, 2007
Thursday, September 27, 2007
Integration strategies
We use perforce at work. Although people talk a lot of smack about perforce, I actually find it to be generally quite acceptable at what it does.
However, I've been hitting some snags as of late. Ultimately, the issue comes down to branching, and how to keep multiple trees in sync for a particular set of tools.
Although the perforce website has a lot of white papers on various subjects, I haven't really found anything there that describes what I'm looking for. Even the white paper on branching describes exactly what I don't want. What I really want is a way to say: "Hey, even though I need to have this file replicated to these 17 different locations, they're really the same file. And if someone changes one of them, I want you to think of that as changing all of them."
Unfortunately, this is functionality that perforce adamently denies has any place in the real world. Well, here I am, maintaining around 17 trees, and I'm telling you that this functionality would probably remove about three hours a day from my work day.
The usual way we deal with this is to relocate the relevant tools outside of the branched codebase, and then point everything at the new location. Unfortunately, this is a manual, time consuming process. It sucks, and I don't like repeating work again and again (which is pretty much what I'm doing now).
So the question I put out there is: does anyone have a better way than these two methods? To sum up, here they were:
However, I've been hitting some snags as of late. Ultimately, the issue comes down to branching, and how to keep multiple trees in sync for a particular set of tools.
Although the perforce website has a lot of white papers on various subjects, I haven't really found anything there that describes what I'm looking for. Even the white paper on branching describes exactly what I don't want. What I really want is a way to say: "Hey, even though I need to have this file replicated to these 17 different locations, they're really the same file. And if someone changes one of them, I want you to think of that as changing all of them."
Unfortunately, this is functionality that perforce adamently denies has any place in the real world. Well, here I am, maintaining around 17 trees, and I'm telling you that this functionality would probably remove about three hours a day from my work day.
The usual way we deal with this is to relocate the relevant tools outside of the branched codebase, and then point everything at the new location. Unfortunately, this is a manual, time consuming process. It sucks, and I don't like repeating work again and again (which is pretty much what I'm doing now).
So the question I put out there is: does anyone have a better way than these two methods? To sum up, here they were:
- Code lives in an area that's branched, and changes need to be propogated everywhere to keep everything in sync.
- Code lives in an area that isn't branched, but this is usually a hindsight realization so it requires manual updates of all related tools to pick the tool up from the new location.
Wednesday, September 26, 2007
Where are the books for experienced programmers?
Recently, I've been reading books on how to develop websites using "Web 2.0" techniques (basically AJAX). What I've noticed about these books--and even other coding books in my library--is that there is a serious lack of books for the experienced, well-disciplined programmer.
I honestly find it a little insulting that every book on C++ feels the need to re-explain to me APIE (Abstraction, Polymorphism, Inheritance, Encapsulation). As does every Java book. As does every Python book. Even books that claim to cater to the experienced or advanced programmer always recover these topics.
Of course, I've heard of projects like Rosetta Code, but that's not really what I'm looking for either. For one thing, there are only 87 examples, not even covering topics I'm really interested in. (An example of a topic I'd like to see is, "How to remove items from a collection based on a predicate?") Yes, it's wiki. Yes, I could go write the article myself. No thanks.
I guess what I really want to find are books that tell you the right way to perform tasks in a certain language, or why you would prefer one method over another. For example, in which situations should I prefer to use a vector instead of a map? (I'll give you a hint, even in key-value situations there are reasons to sometimes prefer a vector to a map).
For example, let's say I'm writing a new piece of C++ code. Should I use the stl? Almost always. Is there a good logging subsystem out there that I could use to avoid rewriting a new one? Are there any libraries I should avoid? Boost.
I don't need to relearn why I should write objects or what should go into an object. Tell me how to define an object, how to use inheritance, how abstraction is implemented. Give me actual, realistic costs of making design tradeoffs. For example, how much will it cost me to call a virtual function? Is there a way I can mitigate this inside of a single class, if I really know what the type of the class is?
I'm sure, one of these days, someone will get it. Till then, I'll just continue to suffer in silence.
I honestly find it a little insulting that every book on C++ feels the need to re-explain to me APIE (Abstraction, Polymorphism, Inheritance, Encapsulation). As does every Java book. As does every Python book. Even books that claim to cater to the experienced or advanced programmer always recover these topics.
Of course, I've heard of projects like Rosetta Code, but that's not really what I'm looking for either. For one thing, there are only 87 examples, not even covering topics I'm really interested in. (An example of a topic I'd like to see is, "How to remove items from a collection based on a predicate?") Yes, it's wiki. Yes, I could go write the article myself. No thanks.
I guess what I really want to find are books that tell you the right way to perform tasks in a certain language, or why you would prefer one method over another. For example, in which situations should I prefer to use a vector instead of a map? (I'll give you a hint, even in key-value situations there are reasons to sometimes prefer a vector to a map).
For example, let's say I'm writing a new piece of C++ code. Should I use the stl? Almost always. Is there a good logging subsystem out there that I could use to avoid rewriting a new one? Are there any libraries I should avoid? Boost.
I don't need to relearn why I should write objects or what should go into an object. Tell me how to define an object, how to use inheritance, how abstraction is implemented. Give me actual, realistic costs of making design tradeoffs. For example, how much will it cost me to call a virtual function? Is there a way I can mitigate this inside of a single class, if I really know what the type of the class is?
I'm sure, one of these days, someone will get it. Till then, I'll just continue to suffer in silence.
Thread-safe printing in Python
Recently, a coworker was having issues printing from multiple threads in his python program.
After a little googling, I came upon this discussion which covered this exact topic.
At the lowest level, python appears to be threadsafe wrt a single file handle, which is good. Unfortunately, when you use the print statement, an implicit '\n' is added for you, and this apparently results in a second low-level write call, which is a seperate mutex grab.
As a result, you often get lines of text that look like this:
In this situation, you basically have two choices. You could replace your print statements with a custom written print function that grabs a mutex and adds a trailing '\n', or you could use the logging module. Even though the threadsafe print module is very short, I'd still suggest that the 'right thing' to do here is to just use the logging module.
When you decide in the future that you want to log to a tcp connection on another server, your future self will pat yourself on the back that you just used logging up front.
Cheers,
After a little googling, I came upon this discussion which covered this exact topic.
At the lowest level, python appears to be threadsafe wrt a single file handle, which is good. Unfortunately, when you use the print statement, an implicit '\n' is added for you, and this apparently results in a second low-level write call, which is a seperate mutex grab.
As a result, you often get lines of text that look like this:
This text comes from Thread 1.This text comes from Thread2.
< Empty Line >
This text comes from Thread 1.This text comes from Thread2.
< Empty Line >
In this situation, you basically have two choices. You could replace your print statements with a custom written print function that grabs a mutex and adds a trailing '\n', or you could use the logging module. Even though the threadsafe print module is very short, I'd still suggest that the 'right thing' to do here is to just use the logging module.
When you decide in the future that you want to log to a tcp connection on another server, your future self will pat yourself on the back that you just used logging up front.
Cheers,
Tuesday, September 25, 2007
Olivier could be a Visual Studio Installer Model
One of my fellow nvidians, Olivier, writes in his blog Mutable Conclusions. Prominently on his website, he features a picture of himself. I've included a copy here:

I've teased him about this mercilessly, but I think his picture would've been a perfect include in the Microsoft Visual Studio installer. Judge for yourself.
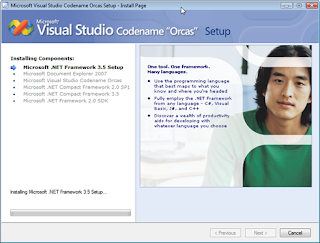

I've teased him about this mercilessly, but I think his picture would've been a perfect include in the Microsoft Visual Studio installer. Judge for yourself.

Monday, September 24, 2007
I'm a comic!
A friend of mine is a (yet undiscovered) great artist. She does phenomenal 2-D work, and keeps up a daily sketch site. I only recently discovered her site, but I was excited to see that I'd been rendered as a comic.
I feel the representation is fairly accurate.
I feel the representation is fairly accurate.
Sunday, July 15, 2007
Python: Enforcing Interface Requirements
I write a moderate amount of Python code for work. Not necessarily as much as I'd like, but that's a topic for another post.
A short while back, one of my coworkers asked this question at lunch: "If I'm writing an interface that I want other people to be able to use with their own new types, how do I ensure that I write my code in such a way that they can clearly and easily understand the interface that they need to implement? As an additional problem, how do I ensure that I don't accidentally break my interface requirements?"
Now, if you've written much python code at all, you're probably familiar with the term 'duck typing', which basically exerts that "if it quacks like a duck and walks like a duck, it might as well be a duck." This is probably one of python's greatest strengths as it reduces the syntactic complexity of 'templated' code; by default all functions work with all types that match the implicit interface that is their implementation.
The unfortunate side effect of duck-typing is that in order to see the exact interface that you would need to implement for an API to work with, you'd have to pore through the entire codebase of the API (!!). Clearly, that wouldn't work at all. After a bit of discussion, we came up with the following solution:
A short while back, one of my coworkers asked this question at lunch: "If I'm writing an interface that I want other people to be able to use with their own new types, how do I ensure that I write my code in such a way that they can clearly and easily understand the interface that they need to implement? As an additional problem, how do I ensure that I don't accidentally break my interface requirements?"
Now, if you've written much python code at all, you're probably familiar with the term 'duck typing', which basically exerts that "if it quacks like a duck and walks like a duck, it might as well be a duck." This is probably one of python's greatest strengths as it reduces the syntactic complexity of 'templated' code; by default all functions work with all types that match the implicit interface that is their implementation.
The unfortunate side effect of duck-typing is that in order to see the exact interface that you would need to implement for an API to work with, you'd have to pore through the entire codebase of the API (!!). Clearly, that wouldn't work at all. After a bit of discussion, we came up with the following solution:
- API Interfaces should begin by asserting that the arguments passed in match a specified, required Interface. This takes care of the first half of the problem, because a developer needs only to look just inside the function to determine which Interface class needs to be implemented (or derived from, if the developer so chooses).
- The objects passed in should be limited (for the duration of the function) to only expose the explicit members that the interface allows for. This solves the second half of the problem, because it makes it impossible to peek under the covers other than what the Interface allows for.
class __frozen_iface (object):Then, client code would do something like this:
def __init__ (self, ifspec, instance):
for member in inspect.getmembers(ifspec):
if member[0].startswith ("__"):
continue
if not inspect.ismethod (member[1]):
continue
instance_attr = getattr (instance, member[0])
if instance_attr.im_func == member[1].im_func:
raise AttributeError, "Class '%s' has interface class implementation of attribute '%s'" % (instance.__class__, member[0])
# bypass our internal __setattr__ since that will raise an exception
object.__setattr__ (self, attr_name, instance_attr)
def __setattr__ (self, name, value):
# prevent anyone from accidentally assigning new attributes
raise AttributeError, "Attempt to set an attribute '%s' for frozen interface class '%s'" % (name, self)
def UseInterface(ifspec, instance):
return __frozen_iface (ifspec, instance)
class Renderable(object):This could also be trivially wrapped into a decorator so your code could look like this:
def Draw(self, context):
abstract # Raises an execption if we get here.
def RenderObject(someRenderable):
someRenderable = UseInterface(Renderable, someRenderable)
dir(someRenderable) # Outputs only 'Draw'
class Renderable(object):
@Interface(Context)
def Draw(self, context):
abstract # Raises an execption if we get here.
PS: Thanks to JimR for the cool implementation of __frozen_iface.
Friday, May 4, 2007
Structured Cleanup: Avoiding gotos
I think everyone in our profession has to write code, at some point, that grabs multiple resources, then do something.
And unconditionally, that code needs to make sure to back out any resource acquisitions in cases of intermediate failure, and only back out the resources that are actually grabbed.
Normally, you see this kind of code for that purpose:
I have two problems with this code:
The beauty of this code is its simplicity. By taking advantage of the guarantee that destructors will always be called upon exiting scope*, we ensure that a and b will always either be dealt with properly, or will be freed. Furthermore, while we do have to update the function in two places when we add a new resource acquisition, we do not have to worry about what order we TakeOwnership! Additionally, this pattern lends itself towards all sorts of resource acquisitions, whether they are mutex grabs, file reads, allocations as we've done above, etc. We can make this pattern fit virtually any resource acquisition pattern, and ensure that we have consistent, future-proof, goto-free code.
Don't get me wrong, gotos have their place. Just not in structured cleanup code.
* C++ doesn't always guarantee that destructors will be called. Any abnormal program termination, including explicit calls to exit, abort, terminate, pure virtual calls, exceptions thrown from exceptions (or destructors), or infinite loops will prevent destructors from being called.
And unconditionally, that code needs to make sure to back out any resource acquisitions in cases of intermediate failure, and only back out the resources that are actually grabbed.
Normally, you see this kind of code for that purpose:
int doStuff(void) {
char* a = (char*) malloc(100);
if (!a) goto failure_a;
char* b = (char*) malloc(100);
if (!b) goto failure_b;
// do some stuff
// Want to keep a and b around.
return 0;
// Future proofing, for when we add c.
free(b);
failure_b:
free(a);
failure_a:
return -1;
}
I have two problems with this code:
- Updating this code requires updating both the allocation semantics and the 'free' semantics.
- This doesn't lend itself towards any sort of 'pattern' which we can reuse for other things, like grabbing a mutex, semaphore, etc.
template <typename T>
class RollbackAllocator
{
RollbackAllocator(int countToAlloc) : mAllocated(0) { mAllocated = new T[countToAlloc]; }
~RollbackAllocator() { if (mAllocated) delete [] mAllocated; }// For easy-to-read client code, no one should take ownership of allocated
// objects untilthere are no further failure conditions possible. This same
// technique can be used for
// ANY resource acquisition, whether it's an allocation of memory,
// grabbing a socket, mutex,semaphore, reading a file, etc.
T* TakeOwnership() { T* retVal = mAllocated; mAllocated = 0; return retVal; }
T* mAllocated;
}
int doStuff(void)
{// If any fails, it'll throw an exception and the others will be cleaned up.
RollbackAllocator<char> aAlloc(100);
RollbackAllocator<char> bAlloc(100);
// do additional things that could fail.
a = aAlloc.TakeOwnership();
b = bAlloc.TakeOwnership();
return 0;
}
The beauty of this code is its simplicity. By taking advantage of the guarantee that destructors will always be called upon exiting scope*, we ensure that a and b will always either be dealt with properly, or will be freed. Furthermore, while we do have to update the function in two places when we add a new resource acquisition, we do not have to worry about what order we TakeOwnership! Additionally, this pattern lends itself towards all sorts of resource acquisitions, whether they are mutex grabs, file reads, allocations as we've done above, etc. We can make this pattern fit virtually any resource acquisition pattern, and ensure that we have consistent, future-proof, goto-free code.
Don't get me wrong, gotos have their place. Just not in structured cleanup code.
* C++ doesn't always guarantee that destructors will be called. Any abnormal program termination, including explicit calls to exit, abort, terminate, pure virtual calls, exceptions thrown from exceptions (or destructors), or infinite loops will prevent destructors from being called.
Wednesday, April 25, 2007
I don't normally do this...
... journaling (I refuse to call this blogging) is not something I normally do.
Anyways, my actual website, Lexical-Ambiguity is perpetually down because I'm too busy with other things to actually spend time making it work.
Here, the three of you that read this will probably find the following categories of information:
Anyways, my actual website, Lexical-Ambiguity is perpetually down because I'm too busy with other things to actually spend time making it work.
Here, the three of you that read this will probably find the following categories of information:
- Code related topics
- Exercise, fitness and weight-lifting information
- Stuff about gaming
- Stuff about books
Subscribe to:
Comments (Atom)

